Python 内置的序列类型
前言
本文介绍 Python 3 中按不同数据结构实现的类型分类、其中的序列类型的分类,并通过一些实例展示这些不同的序列类型的特点。
本文中的命令行示范,都是基于以下环境:
- 操作系统: CentOS 7
- Python:
3.7.03.7.9 (更新)
Python 的数据类型
按数据结构的分类
需要先阐明,这里说的是数据结构,而不是数据模型,虽然在部分书籍或教程中,两者可能是同一个意思。Python 的官方文档 Language Reference 的 第三章,介绍了什么是数据模型,它是一个泛称,所有和数据相关的,比如对象、它的值、它的类型等,都是对数据模型的一个描述。而数据结构,是指 Python 中,对象群体存储方式的描述。把这些不同的存储方式,按照一些特性来分类,就是按数据结构的分类。
Python 的数据结构,大体上可以分为以下三类:
序列(Sequences)类型:一个有序集,可以以非负整数作为下标索引,访问序列中的元素,也支持切片(slice)等操作,如字符串(str)、元祖(tuple)、列表(list)等;集合(Sets)类型:由不重复的、不可变的(immutable)元素组成的一个无序集,由于是无序,所以无法通过下标索引来访问元素,但支持迭代遍历,如普通集合(set)、冻结集合(frozenset)等;映射(Mappings)类型:包含一系列键值对应关系的无序集合,其中键是不可重复的、不可变的元素,值是任意的对象,不支持以非负整数作为下标索引访问,但可以用键索引访问,支持迭代遍历,如字典(dict)。
不同类型的特点
这里有一些知识点,可以帮助我们更好地理解:
- 以非负整数作为下标索引进行访问的操作,唯序列类型独有,优点是访问速度快。
集合,不支持随机访问,但可以迭代遍历,也支持交集、并集等操作。顾名思义,通常用于集合相关的操作。映射类型中的值,是可散列(hashable)类型。可散列类型,是指可以通过散列算法,把该类型的对象映射为一个固定长度的值(索引)。简单地说,就是可以为这个对象标上一个唯一的ID,当你访问该对象的时候,Python 内部用该ID来访问。 这种方式并不是原始的随机访问,但通过散列算法实现索引,优点是查询速度快。- 既然可散列类型是通过映射为一个唯一的ID来进行索引,所以可散列类型通常也是
不可变(immutable)类型。Python 的数据结构中,集合中的元素,以及映射中的键(key),必须是可散列类型,也是不可变类型。同理,它们也不可重复(集合中没有重复的元素,映射中没有重复的键)。 - 关于三种类型查询元素的效率,本人将单独写篇文章来进行比较。
我们来看一些具体的例子。
(1)
|
|
上述例子中,序列类型 list 内的元素可以用下标来访问;集合类型 set 内的元素无法通过下标索引访问,但是可以迭代遍历;dict 不能像 list 那样,通过数字下标索引访问元素,但可以用键作为索引,访问对应的值,也支持迭代遍历。
(2)
|
|
通过这个例子,我们可以看到,list 中的元素可以是任何类型,无论是 hashable 或 unhashable,但 set 中的元素必须是 hashable,dict 中的 key 也必须是 hashable。所以那些可变的、unhashable 类型的对象,无法用作 set 的元素和 dict 的 key。
序列类型的分类
上一节我们介绍了 Python 按数据结构特点,可以分为三大类。现在,我们来看一下,其中的序列类型,又可以如何区分成一些不同的子类。
按是否能存放不同类型的元素来区分
某个序列类型中,如果包含对其它对象的引用,即可以包含不同类型的对象,这种序列称为容器(container)序列。如果包含的对象,只能是同一种类型,这种序列称为非容器序列,有些书上也把它称为扁平(flatten)序列。这里我们暂且用扁平序列这个词。
容器序列包括:list,tuple,collections.deque;
扁平序列包括:str,bytes,bytearray,memoryview,array.array ;
容器序列和扁平序列在实现上主要区别,在于存放元素对象的方式上:
容器序列中存放的是它们所包含的任意类型的对象的引用,这些对象在内存中是分散的block;而扁平序列存放的数据往往是一段连续的内存空间。由此可见扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
按是否可变来区分
序列类型如果按照它自己是否可变(元素可增减,元素的值可被修改)来区分,可以分为可变序列和不可变序列。
可变序列包括:list,bytearray,array.array,collections.deque,memoryview ;
不可变序列包括:tuple,str,bytes ;
下面的 UML 类图展示了几抽象类的继承关系:
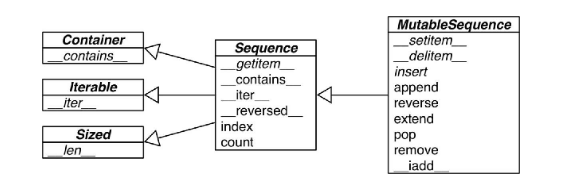
可以看到,在 Python 的内部实现上,可变序列(MutableSequence)类型从普通序列(不可变类型)中继承了一些方法,并在此基础上增加了一些修改序列对象的操作,比如:insert、append、reverse 等等。
序列的可变性
上一节讲述的序列的可变性,是比较重要的概念,也是容易引起误解的地方。比如,我们说 tuple 类型是不可变类型,但是如果你在交互式命令行运行以下程序,它却可以正常运行:
|
|
这是为什么呢?
前面本人提到过,有些序列中存放的是任意类型对象的引用。上面的语句中定义了一个 tuple 对象,其中的元素包括一个整形数值,一个列表,一个字符串:
这个 tuple 对象,在内存中的结构像这个样子:
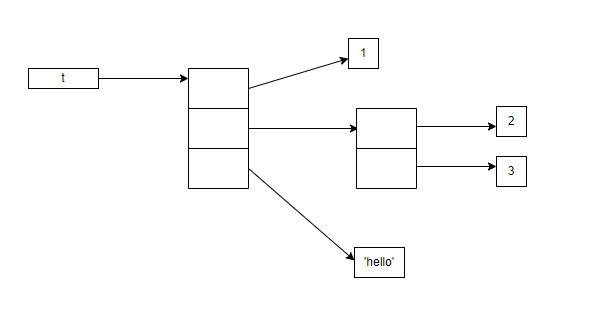
’t’只是一个引用(reference),指向一个 tuple 对象,tuple 对象的内存空间里存放的三个元素的值也是引用,分别指向整形数值1、一个 list 对象、一个字符串。当我们说一个对象是否可变,指的是这个对象自身的内容是否可变,比如 tuple 对象是否会删除一个元素、增加一个元素、某个元素的值改变(指向另一个对象),而并不是指 tuple 对象内某个元素指向的对象是否发生了变化。同理,该定义适用于其它类型。
所以,在前面的例子中,虽然 tuple 对象是不可变的,但它的第二个元素指向的对象是个 list,它是可变的,当我们执行 “t[1].append(5)” 时,tuple 的第二个元素的值还是原来的地址,指向那个 list 对象,但 list 对象的内容发生了改变,新的 tuple 对象在内存中是这个样子:
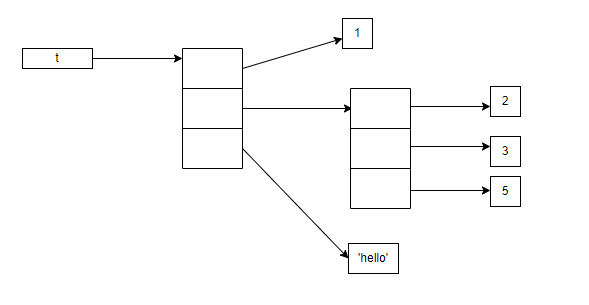
不可变性和可散列性
既然定义了什么是可变性,那么我们就要重点来看一看不可变性和可散列性是否是同一个意思。
先说结论,可散列性(hashable)的定义比不可变性(immutable)更严谨,一个对象如果是可散列的,那么它一定是不可变的,反之却不成立。
换句话说,可散列性是不可变性的充分非必要条件。
那么到底什么是可散列性呢?第一节中本人大致描述了一下可散列性,这里再摘取 Python词汇表 中关于可散列性的完整定义:
hashable
An object is hashable if it has a hash value which never changes during its lifetime (it needs a
__hash__()method), and can be compared to other objects (it needs an__eq__()method). Hashable objects which compare equal must have the same hash value.Hashability makes an object usable as a dictionary key and a set member, because these data structures use the hash value internally.
Most of Python’s immutable built-in objects are hashable; mutable containers (such as lists or dictionaries) are not; immutable containers (such as tuples and frozensets) are only hashable if their elements are hashable. Objects which are instances of user-defined classes are hashable by default. They all compare unequal (except with themselves), and their hash value is derived from their
id().
翻译成中文:
可散列的
一个对象具有在其生命周期内不会改变的散列值(它需要一个
__hash__()方法),并可以同其他对象进行比较(它需要具有__eq__()方法),那么这个对象就是可散列的。两个比较起来相同的可散列对象,必须要有相同的散列值。可散列性使得对象能够作为字典键或集合成员使用,因为这些数据结构要在内部使用散列值。
大多数 Python 中的不可变的内置对象都是可散列的;可变容器(例如列表或字典)都不可散列;不可变容器(例如元组和 frozenset)仅当它们的元素均为可散列时才是可散列的。 用户自定义类的实例对象默认是可散列的。 它们在比较时一定不相同(除非是与自己比较),它们的散列值的生成是基于它们的
id()。
这段话其实已经把可散列性和不可变性描述得比较清楚了。一个对象如果是可散列的,那么它一定是不可变的,因为可散列对象具有唯一的、不变的散列值;一个对象如果是不可变的,只有当它的元素引用的对象也是可散列的,这个对象才是可散列的。这里最典型的例子就是 tuple,在上一节,本人用例子阐述了 tuple 对象本身是不可变对象,但 tuple 对象是否是可散列的呢?要看具体的例子:
|
|
执行结果:
|
|
可以看到,一个 tuple 对象内的元素引用的是另一个可散列的 tuple 对象(t1)或引用的是一个可散列的冻结集合(t2),这个 tuple 对象就是可散列的。但如果它的某个元素引用的是一个不可散列的列表(t3),那么它是不可散列的。
关于可散列性的更多细节,本人将在另一篇文章中单独展开介绍。
参考
https://docs.python.org/3.7/reference/datamodel.html
https://docs.python.org/3/glossary.html
「 您的赞赏是激励我创作和分享的最大动力! 」



- 原文链接:https://zhuyinjun.me/2019/sequences_data_type_in_python/
- 版权声明:本创作采用 CC BY-NC 4.0 国际许可协议,非商业性使用可以转载,但请注明出处(作者、链接),商业性使用请联系作者获得授权。