高频行情数据的数据库选型
需求
行情数据是证券交易的核心数据,通常包括两部分:委托数据和成交数据。委托数据是我们通常能在股票软件上看到的委买委卖单,它是所有证券交易者输入的委托买卖证券的订单,根据委托档位的多少,可以分为一档、五档、十档等行情;成交数据就是证券订单获得成交后的数据,包括成交量、成交价、成交额等。委托数据和成交数据合在一起,称为TAQ(Trades and Quotes)行情。
行情数据最大的特点就是高频更新、数据量大。以沪深两市 level 2 行情为例,共有6000多个symbol(包括上市企业、基金、债券等),level 2 行情中盘口数据以快照(snapshot)方式每三秒更新一次,逐笔成交和逐笔委托以毫秒级别更新,这意味着行情数据属于高频更新的数据。如果把行情数据落地,那么上交所的一天的行情数据文件,大概有12~15GB,深交所有20~25GB,两市总和大概32~40GB。
这里仅仅是考虑沪深的股票行情,如果加上上期所、大商所、郑商所等其他商品期货交易所,甚至海外市场,那么每天行情数据量将非常惊人。
高频更新和庞大的数据量,意味着设计的系统将主要面对两个问题:
- 如何高效地接受、处理、分发实时行情数据,供交易员实时交易,也就是低延迟技术;
- 如何高效地存储历史行情数据,供交易员查询、回测,这涉及到数据存储方案的选型与设计。
这里先摸索摸索第二个问题,即数据库的选型。
数据存储技术
数据存储相关的技术比较多样。典型的数据存储技术包括:
- 文件格式:CSV, HDF5 等;
- 序列化数据结构;
- 关系型数据库(SQL):Oracle,MySQL,PostgreSQL;
- 非关系型数据库(NoSQL):MongoDB,CouchDB,Redis,KDB,InfluxDB,TimescaleDB
行情数据的特点
如果对数据的读写效率要求较高,那可以先排除 CSV 文件存储和序列化数据结构存储。CSV 文件存储通常用来处理少量矩阵数据,支持用Excel打开加工,序列化数据结构把特定结构的数据以数组形式存储在文件系统上,由于是顺序存储且缺乏索引机制,所以查询、插入、删除非常低效。
行情数据本质上是一种时间序列数据,它通常具有以下特点:
- 一次写入:接受一次完整的行情数据存入数据库后,一般不会再修改;
- 尾部写入:新录入的行情数据一般添加至末尾,因为行情数据按时间先后排序;
- 频繁查询和读取:行情数据存入数据库后,量化交易员会频繁读取从而回测策略;
- 多次删除:对于无用的或错误的数据,可以直接删除。
这些特点意味着理想中的数据库,可以牺牲一些写入的效率,尤其是头部写入或者中插,但是对于尾部写入、查询、删除必须高效。另外由于行情数据的键是时间戳,所以需要数据库对时间戳字段的支持较好(支持高效查询一段时间内的数据)。下面来看一下不同类型的数据库的特点。
关系型数据库
关系型数据库是市面是的主流数据库,像被企业广泛使用的 Oracle,MySQL,以及近几年流行的 PostgreSQL。关系型数据库的优缺点:
✅ ACID特性
✅ 二维表结构容易理解
✅ 支持 SQL
❌ 为了维护一致性导致读写性能较差
❌ 固定的表结构,不灵活
❌ 表之间的数据耦合性强,不易扩展
非关系型数据库
非关系型数据库不是严格意义上的数据库,而是一种把数据结构化存储的方法。它的优缺点包括:
✅ 读写性能较高
✅ 数据之间无需较强的耦合性,容易扩展
✅ 数据格式可以多样性:key-value,文档,图片,时间序列等
❌ 不提供 SQL 支持
❌ 一般不保证 ACID
非关系型数据库按照数据存储的格式,又分为:
- key-value 形式,代表产品:Redis
- 文档形式,代表产品:MongoDB,CouchDB
- 时间序列形式:代表产品:KDB,InfluxDB,TimescaleDB
比较
前面说过,行情数据的特点是量大、读写频繁(一次写入,但写入频率高),所以可以先排除传统的 SQL 数据库;在余下的 NoSQL 中,MongoDB 是一种文档型数据库,优点是牺牲强一致性换来较高的访问性能、支持大容量存储,缺点是占用空间过大、不支持复杂查询;Redis 是以 key-value 方式存储数据,内部用了 hash 结构支持高效的查询,优点是性能高、丰富的数据类型、原子性,缺点是数据库容量受到物理内存限制,不能用作海量数据的高性能读写。本人不认为这两个数据库适用于行情数据。
剩下的数据库就是时间序列型数据库了。从类型来看,就可以感觉到这类数据库天生就适合金融类数据,因为大部分金融类数据都是时间序列数据。时间序列型数据库的几个典型产品包括:KDB,InfluxDB,TimescaleDB,这三个产品的大体介绍和比较可以参考:https://db-engines.com/en/system/InfluxDB%3BKdb%3BTimescaleDB
三个数据库都支持对时间序列数据的处理。但 KDB 除了支持时间序列特性以外,还支持矩阵型数据。KDB 是用一门称为 Q 的语言开发而成,采用列式存储方式,被官方称为世界上最快的时间序列数据库,许多金融机构都使用 KDB 作为金融数据解决方案。InfluxDB 和 TimescaleDB 是比较年轻的数据库,尤其是 InfluxDB,近年来在金融行业越来越流行,InfluxDB 的一个优势就是它提供免费试用版。
既然行情数据对查询和读取的效率要求比较高,那我们来看看这些时间序列数据库的性能比较。网上有人分享过比较结果:

数据来源:https://www.timestored.com/time-series-data/time-series-database-benchmarks
左侧是不同的比较基准,T (trade)开头表示交易相关数据,O(order)开头表示委托单相关数据。比如,T-V1 表示一日内每分钟的平均交易量,O-B1 表示找出一周内最高的委托买价(bid price),具体细节见下图:
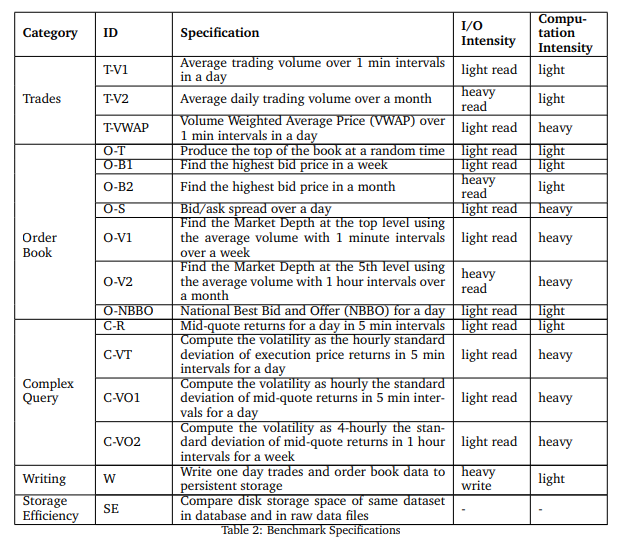
从上面的性能比较结果可以看到,KDB 在数据的读取查询中,占有绝对的优势,除了在计算 T-V2(一个月内平均每天交易量)上略逊于 InfluxDB 外,其它部分都比 InfluxDB 和 TimescaleDB 高效。另外,比较对象中还包括了 ClickHouse。ClickHouse 是一个关系型数据库,不过它支持时间序列作为次级存储方式,在行情数据的读写性能上,比 Timescale 更高效。
网上还有许多类似的文章,基本都得出类似结果。
总结
基于以上比较和分析,在高频行情数据的存储技术方面,个人比较推荐的数据库选型是:
KDB > InfluxDB > ClickHouse
(注:以上比较不考虑产品的成本)
参考文章
https://db-engines.com/en/system/ClickHouse%3BInfluxDB%3BKdb%3BTimescaleDB
https://www.timestored.com/time-series-data/time-series-database-benchmarks
「 您的赞赏是激励我创作和分享的最大动力! 」



- 原文链接:https://zhuyinjun.me/2023/select_db_for_market_data/
- 版权声明:本创作采用 CC BY-NC 4.0 国际许可协议,非商业性使用可以转载,但请注明出处(作者、链接),商业性使用请联系作者获得授权。